Introduction
This article is the second in the series dedicated to extending TrackMate with your own modules. Here we focus on creating feature analyzers: small algorithms that calculate one or several numerical values for the TrackMate results. The previous article focused on writing edge analyzers: algorithms that allocate a numerical value to the link between two spots.
In this article, we will create a feature analyzer for tracks that calculate numerical values for whole tracks. To make it simple, and also to answer the request of a colleague, we will make an analyzer that reports the location of the starting and ending points of a track.
Actually, we will not learn much beyond what we saw previously. The only little change is that our analyzer will generate 6 numerical values instead of 1. We will use the SciJava discovery mechanism as before, but just for the sake of it, we will introduce how to disable modules.
Track analyzers
All the track feature analyzers must implement TrackAnalyzer interface. Like for the EdgeAnalyzer interface, it extends both
- FeatureAnalyzer that helps you declaring what you compute,
- and TrackMateModule, that is in charge of the integration in TrackMate.
The only changes for us are two methods specific to tracks:
public void process( final Collection< Integer > trackIDs, final Model model );
the does the actual feature calculation for the specified tracks, and
public boolean isLocal();
that specified whether the calculation of the features for one track affects only this track or all the tracks. For the discussion on local vs non-local feature analyzers, I report you to the previous article item.
Track feature analyzer header
Like all TrackMate modules, you need to annotate your class to make it discoverable by TrackMate. It takes the following shape:
@Plugin( type = TrackAnalyzer.class )
public class TrackStartSpotAnalyzer implements TrackAnalyzer
{
// etc...
and that’s good enough.
Declaring features
Declaring the features your provide is done as before. This time, a single analyzer returns 6 values, so you need to declare them. Here is the related code:
@Plugin( type = TrackAnalyzer.class )
public class TrackStartSpotAnalyzer implements TrackAnalyzer
{
private static final String KEY = "TRACK_START_SPOT_ANALYZER";
public static final String TRACK_START_X = "TRACK_START_X";
public static final String TRACK_START_Y = "TRACK_START_Y";
public static final String TRACK_START_Z = "TRACK_START_Z";
public static final String TRACK_STOP_X = "TRACK_STOP_X";
public static final String TRACK_STOP_Y = "TRACK_STOP_Y";
public static final String TRACK_STOP_Z = "TRACK_STOP_Z";
private static final List< String > FEATURES = new ArrayList< String >( 6 );
private static final Map< String, String > FEATURE_SHORT_NAMES = new HashMap< String, String >( 6 );
private static final Map< String, String > FEATURE_NAMES = new HashMap< String, String >( 6 );
private static final Map< String, Dimension > FEATURE_DIMENSIONS = new HashMap< String, Dimension >( 6 );
static
{
FEATURES.add( TRACK_START_X );
FEATURES.add( TRACK_START_Y );
FEATURES.add( TRACK_START_Z );
FEATURES.add( TRACK_STOP_X );
FEATURES.add( TRACK_STOP_Y );
FEATURES.add( TRACK_STOP_Z );
FEATURE_NAMES.put( TRACK_START_X, "Track start X" );
FEATURE_NAMES.put( TRACK_START_Y, "Track start Y" );
FEATURE_NAMES.put( TRACK_START_Z, "Track start Z" );
FEATURE_NAMES.put( TRACK_STOP_X, "Track stop X" );
FEATURE_NAMES.put( TRACK_STOP_Y, "Track stop Y" );
FEATURE_NAMES.put( TRACK_STOP_Z, "Track stop Z" );
FEATURE_SHORT_NAMES.put( TRACK_START_X, "X start" );
FEATURE_SHORT_NAMES.put( TRACK_START_Y, "Y start" );
FEATURE_SHORT_NAMES.put( TRACK_START_Z, "Z start" );
FEATURE_SHORT_NAMES.put( TRACK_STOP_X, "X stop" );
FEATURE_SHORT_NAMES.put( TRACK_STOP_Y, "Y stop" );
FEATURE_SHORT_NAMES.put( TRACK_STOP_Z, "Z stop" );
FEATURE_DIMENSIONS.put( TRACK_START_X, Dimension.POSITION );
FEATURE_DIMENSIONS.put( TRACK_START_Y, Dimension.POSITION );
FEATURE_DIMENSIONS.put( TRACK_START_Z, Dimension.POSITION );
FEATURE_DIMENSIONS.put( TRACK_STOP_X, Dimension.POSITION );
FEATURE_DIMENSIONS.put( TRACK_STOP_Y, Dimension.POSITION );
FEATURE_DIMENSIONS.put( TRACK_STOP_Z, Dimension.POSITION );
}
/*
* FEATUREANALYZER METHODS
*/
@Override
public List< String > getFeatures()
{
return FEATURES;
}
@Override
public Map< String, String > getFeatureShortNames()
{
return FEATURE_SHORT_NAMES;
}
@Override
public Map< String, String > getFeatureNames()
{
return FEATURE_NAMES;
}
@Override
public Map< String, Dimension > getFeatureDimensions()
{
return FEATURE_DIMENSIONS;
}
Let’s compute them now.
Accessing tracks in TrackMate
In the previous article, we went maybe a bit quickly on how to access data in TrackMate. This is not the goal of this series, but here is a quick recap:
All the track structure is stored in a sub-component of the model called the TrackModel. It stores the collection of links between two spots that builds a graph, and has some rather complex logic to maintain a list of connected components: the tracks.
The tracks themselves are indexed by their ID, stored as an int, that has no particular meaning. Once you have the ID of track, you can get the spots it contains with
trackModel.trackSpots( trackID )
and its links (or edges) with
trackModel.trackEdges( trackID )
Let’s exploit this.
Calculating the position of start and end points
Well, it is just about retrieving a track and identifying its starting and end points. Here is the whole code for the processing method:
@Override
public void process( final Collection< Integer > trackIDs, final Model model )
{
// The feature model where we store the feature values:
final FeatureModel fm = model.getFeatureModel();
// Loop over all the tracks we have to process.
for ( final Integer trackID : trackIDs )
{
// The tracks are indexed by their ID. Here is how to get their
// content:
final Set< Spot > spots = model.getTrackModel().trackSpots( trackID );
// Or .trackEdges( trackID ) if you want the edges.
// This set is NOT ordered. If we want the first one and last one we
// have to sort them:
final Comparator< Spot > comparator = Spot.frameComparator;
final List< Spot > sorted = new ArrayList< Spot >( spots );
Collections.sort( sorted, comparator );
// Extract and store feature values.
final Spot first = sorted.get( 0 );
fm.putTrackFeature( trackID, TRACK_START_X, Double.valueOf( first.getDoublePosition( 0 ) ) );
fm.putTrackFeature( trackID, TRACK_START_Y, Double.valueOf( first.getDoublePosition( 1 ) ) );
fm.putTrackFeature( trackID, TRACK_START_Z, Double.valueOf( first.getDoublePosition( 2 ) ) );
final Spot last = sorted.get( sorted.size() - 1 );
fm.putTrackFeature( trackID, TRACK_STOP_X, Double.valueOf( last.getDoublePosition( 0 ) ) );
fm.putTrackFeature( trackID, TRACK_STOP_Y, Double.valueOf( last.getDoublePosition( 1 ) ) );
fm.putTrackFeature( trackID, TRACK_STOP_Z, Double.valueOf( last.getDoublePosition( 2 ) ) );
// Et voilà!
}
}
The whole code for the analyzer can be found here.
Wrapping up
Et ca marche !
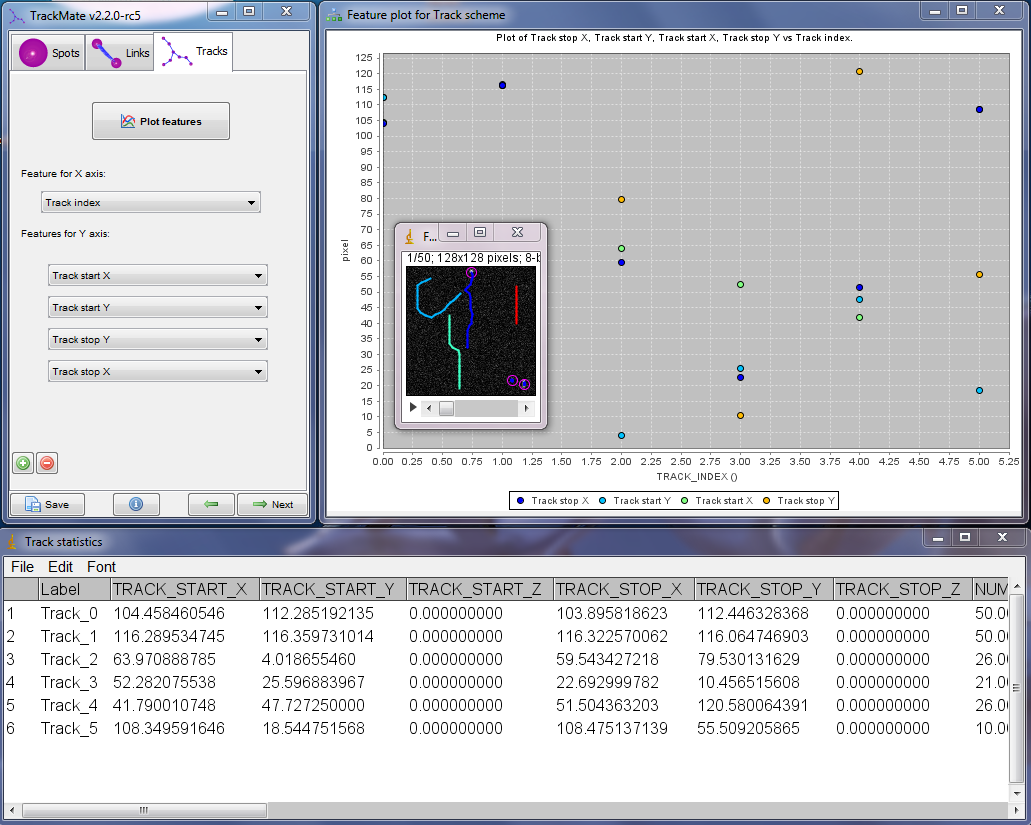
In the next article we will build a spot analyzer and complicate things a bit, by introducing the notion of priority. But before this, a short word on how to disable a module.
How to disable a module
Suppose you have in your code tree a TrackMate module you wish not to use anymore. The trivial way would be to delete its class, but here is another one what allows us to introduce SciJava plugin annotation parameters.
The @Plugin( type = TrackAnalyzer.class ) annotation accepts extra parameters on top of the type one. They all take the shape of a key = value pair, and a few of them allow the fine tuning of the TrackMate module integration.
The first one we will see is the enabled value. It accepts a boolean as value and by default it is true. Its usage is obvious:
If you want to disable a TrackMate module, add the enabled = false annotation parameter.
Like this:
@Plugin( type = TrackAnalyzer.class, enabled = false )
Disabled modules are not even instantiated. They are as good as dead, except that you can change your mind easily. By the way, you can see that the TrackMate source tree has many of these disabled modules…
Jean-Yves Tinevez 14:23, 11 March 2014 (CDT)