The content of this page has not been vetted since shifting away from MediaWiki. If you’d like to help, check out the how to help guide!
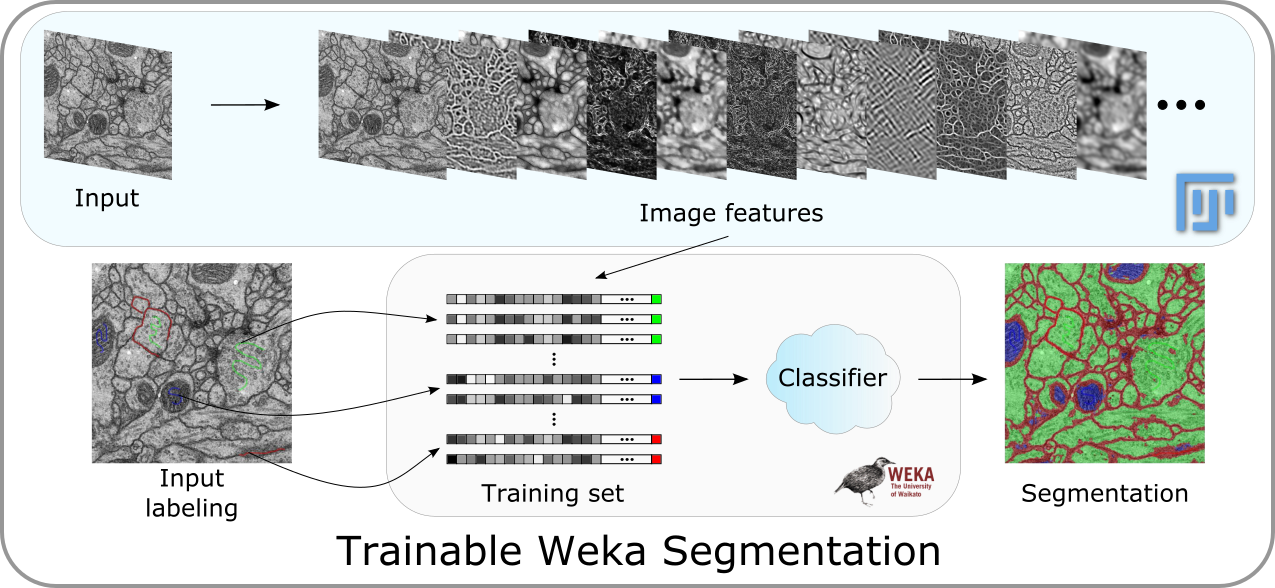
Trainable: this plugin can be trained to learn from the user input and perform later the same task in unknown (test) data.
Weka: it makes use of all the powerful tools and classifiers from the latest version of Weka.
Segmentation: it provides a labeled result based on the training of a chosen classifier.
Introduction
The Trainable Weka Segmentation is a Fiji plugin that combines a collection of machine learning algorithms with a set of selected image features to produce pixel-based segmentations. Weka (Waikato Environment for Knowledge Analysis) can itself be called from the plugin. It contains a collection of visualization tools and algorithms for data analysis and predictive modeling, together with graphical user interfaces for easy access to this functionality. As described on their wikipedia site, the advantages of Weka include:
- freely availability under the GNU General Public License
- portability, since it is fully implemented in the Java programming language and thus runs on almost any modern computing platform
- a comprehensive collection of data preprocessing and modeling techniques
- ease of use due to its graphical user interfaces
Weka supports several standard data mining tasks, more specifically, data preprocessing, clustering, classification, regression, visualization, and feature selection.
The main goal of this plugin is to work as a bridge between the Machine Learning and the Image Processing fields. It provides the framework to use and, more important, compare any available classifier to perform image segmentation based on pixel classification.
The Graphical User Interface
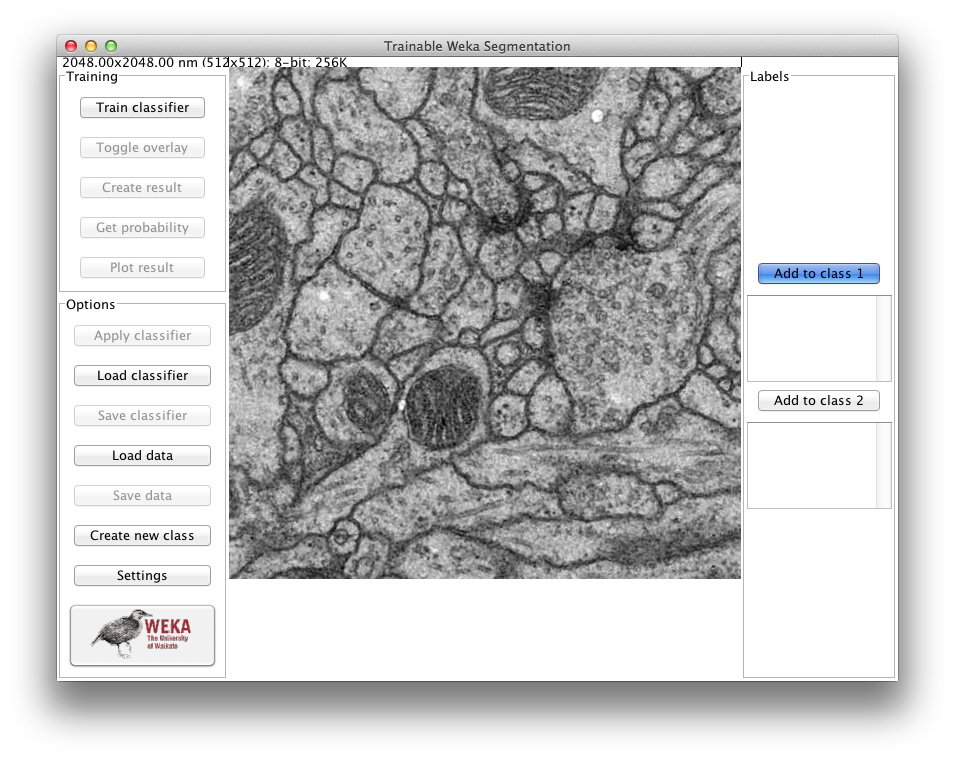 Example of the first look of the plugin window when using it on a TEM image
Example of the first look of the plugin window when using it on a TEM image
Trainable Weka Segmentation runs on any 2D or 3D image (grayscale or color). To use 2D features, you need to select the menu command Plugins › Segmentation › Trainable Weka Segmentation. For 3D features, call the plugin under Plugins › Segmentation › Trainable Weka Segmentation 3D. Both commands will use the same GUI but offer different feature options in their settings.
By default, the plugin starts with two classes, i.e. it will produce binary pixel classification. The user can add traces to both classes using the whole set of tools for ROI (region of interest) drawing available in Fiji. That includes rectangular, round rectangular, oval, elliptical, brush polygon and freehand selections. By default, the freehand selection tool (of 1 pixel width) is automatically selected.
The user can pan, zoom in and out, or scroll between slices (if the input image is a stack) in the main canvas as if it were any other Fiji window. On the left side of the canvas there are two panels of buttons, one for the training and one for the general options. On the right side of the image canvas we have a panel with the list of traces for each class and a button to add the current ROI to that specific class. All buttons contain a short explanation of their functionality that is displayed when the cursor lingers over the buttons.
Training panel
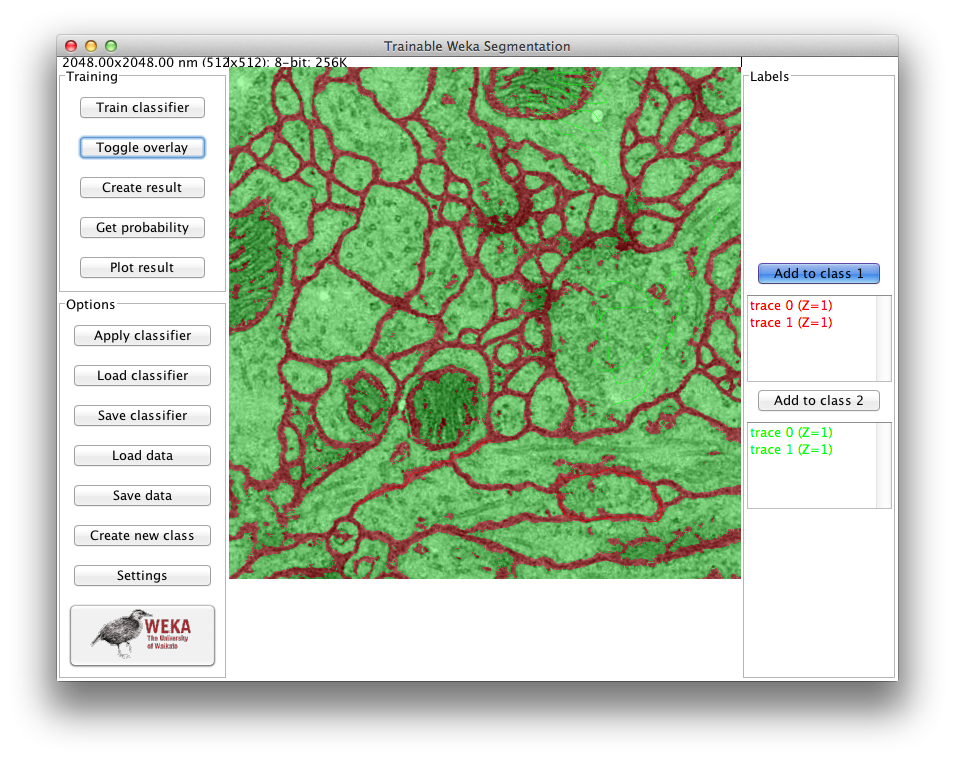 Example of the aspect of the plugin window after training on a TEM image
Example of the aspect of the plugin window after training on a TEM image
Train classifier
This button activates the training process. One trace of two classes is the minimum required to start training. The first time this button is pressed, the features of the input image will be extracted and converted to a set of vectors of float values, which is the format the Weka classifiers are expecting. This step can take some time depending on the size of the images, the number of features and the number of cores of the machine where Fiji is running. The feature calculation is done in a completely multi-thread fashion. The features will be only calculated the first time we train after starting the plugin or after changing any of the feature options.
If the training ends correctly, then the displayed image will be completely segmented and the result will be overlaid with the corresponding class colors. Notice that all buttons are now enabled, since all their functionalities are possible after training.
While training, this button will show the label “STOP”. By clicking on it, the whole training process will be interrupted and the plugin reset to the state previous to the training.
Toggle overlay
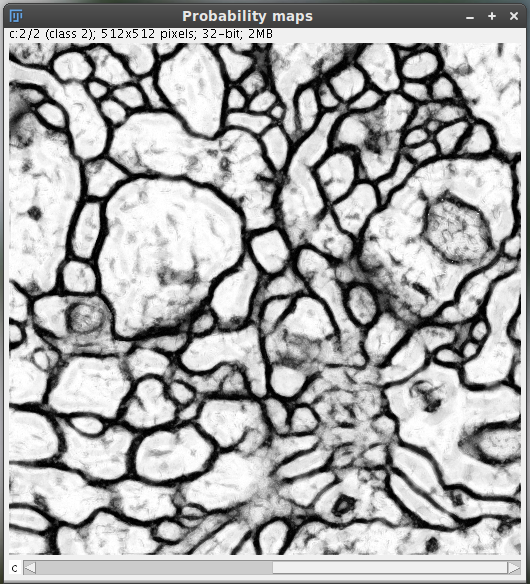 Example of resulting probability map displayed as a hyperstack
Example of resulting probability map displayed as a hyperstack
This button activates and deactivates the overlay of the result image. The transparency of the overlay image can be adjusted in the Settings dialog.
Create result
It creates and displays the resulting image. This image is equivalent to the current overlay (8-bit Color with same class colors). Each pixel is set to the index value of the most likely class (0, 1, 2…).
Get probability
Based on the current classifier, the probability that each pixel belongs to each class is displayed on a 32-bit hyperstack.
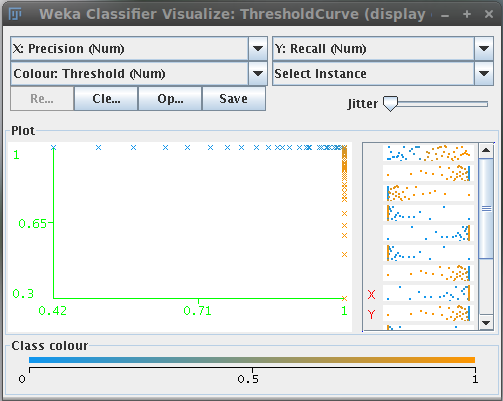
Plot result
This button calls the Weka core to generate the model performance chart, i.e. the ROC, precision/recall, etc. curves based on the training data.
These curves allow to visualize the performance of the classifier based on the different thresholds that can be applied to the probability maps.
{kind=link}
Options panel
Apply classifier
By clicking on this button we can apply the current classifier to any image or stack of images we have in our file system. Two dialogs will pop up to, first, ask the user for the input image or stack and, second, ask if the result should be displayed as a probability map or a segmentation (final classes). Then the plugin will perform the image segmentation based on the current classifier and —consequently— selected features. This may take a while depending on the number and size of the input images and the number of cores of the machine. After finishing, the input image (or stack) and its corresponding segmentation will be displayed.
To convert a probability map into a segmentation, you can use the following Beanshell script from github:
Load classifier
Here we can load any previously saved classifier. The plugin will check and adjust the selected features with the attributes of this new classifier. The classifier file format is the one used in Weka (.model).
Save classifier
It saves the current classifier into a file, under the standard Weka format (.model). This allows us to store classifiers and apply them later on different sessions.
Load data
Here we can load the data (in Weka format) from previous traces on the same or other image or stack. Again, the plugin will check and force the consistency between the loaded data and the current image, features and classes. The input file format is the standard Weka format: ARFF.
Save data
With this button we can save the current trace information into a data file that we can handle later with the plugin or the Weka Explorer itself. The plugin will save the feature vectors derived from the pixels belonging to each trace into an ARFF file at a location chosen by the user. Notice the traces (regions of interests selected by the user) are not saved but only their corresponding feature vectors. To save the ROIs, you can simply use the [https://imagej.net/ij/docs/guide/146-30.html#sub:ROI-Manager… ROI Manager].
Create new class
The default number of classes of the plugin is two, but through this button we can increase up to an arbitrary number. The name of the new classes can be changed on the Settings dialog.
Settings
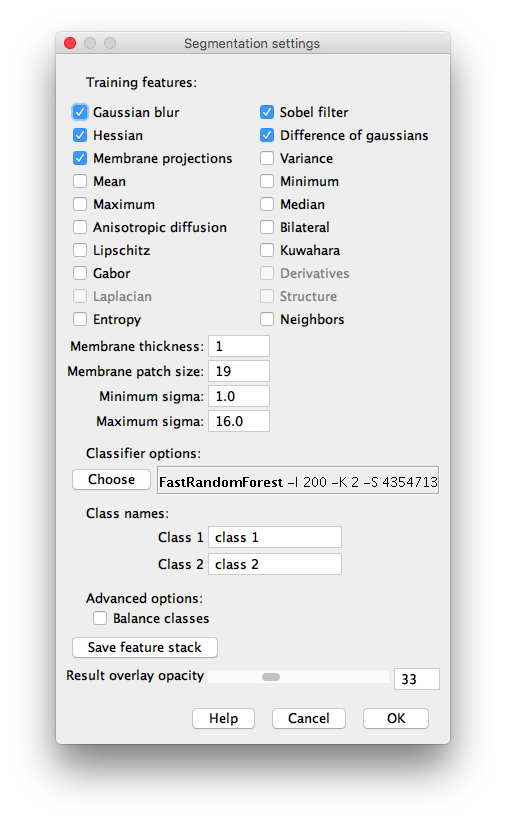 Settings dialog of the Trainable Weka Segmentation plugin (2D features)
Settings dialog of the Trainable Weka Segmentation plugin (2D features)
The rest of tunable parameters of the plugin can be changed on the Settings dialog, which is displayed when clicking on this button.
Training features (2D)
Here we can select and deselect the training features, which are the key of the learning procedure. The plugin creates a stack of images —one image for each feature. For instance, if only Gaussian blur is selected as a feature, the classifier will be trained on the original image and some blurred versions to it with different \(\sigma\) parameters for the Gaussian. \(\sigma\) is commonly equal to \(\sigma_\mathrm{min}, 2\sigma_\mathrm{min}, 4\sigma_\mathrm{min},..., 2^{n-1}\sigma_\mathrm{min}\), where \(2^{n-1}\sigma_\mathrm{min}\le \sigma_\mathrm{max}\). By default \(\sigma_\mathrm{min}=1, \sigma_\mathrm{max}=16\) and therefore \(n=5\).
If the input image is grayscale, the features will be calculated using double precision (32-bit images). In the case of RGB input images, the features will be RGB as well.
The different available 2D image features are:
- Gaussian blur: performs \(n\) individual convolutions with Gaussian kernels with the normal \(n\) variations of \(\sigma\). The larger the radius the more blurred the image becomes until the pixels are homogeneous.
- Sobel filter: calculates an approximation of the gradient of the image intensity at each pixel. Gaussian blurs with \(\sigma\) varying as usual are performed prior to the filter.
- Hessian: Calculates a Hessian matrix \(H\) at each pixel. Prior to the application of any filters, a Gaussian blur with varying \(\sigma\) is performed. The final features used for pixel classification, given the Hessian matrix $$\left(\begin{array}{cc}
a & b\\ c & d\end{array}\right)$$ are calculated thus:
-
- Module: \(\sqrt{a^{2}+bc+d^{2}}\).
- Trace: \(a+d\).
- Determinant: \(ad-cb\).
- First eigenvalue: \(\frac{a+d}{2}+\sqrt{\frac{4b^{2}+(a-d)^{2}}{2}}\).
- Second eigenvalue: \(\frac{a+d}{2}-\sqrt{\frac{4b^{2}+(a-d)^{2}}{2}}\).
- Orientation: \(\frac{1}{2}\arccos\left(4b^{2}+(a-d)^{2}\right)\) This operation returns the orientation for which the second derivative is maximal. It is an angle returned in radians in the range \(\left[-\frac{\pi}{2},\frac{\pi}{2}\right]\) and corresponds to an orientation without direction. The orientation for the minimal second derivative can be obtained by adding (or subtracting) \(\frac{\pi}{2}\).
- Gamma-normalized square eigenvalue difference: \(t^{4}(a-d)^{2}\left((a-d)^{2}+4b^{2}\right)\), where \(t=1^{3/4}\).
- Square of Gamma-normalized eigenvalue difference: \(t^{2}\left((a-d)^{2}+4b^{2}\right)\), where \(t=1^{3/4}\).
-
Difference of gaussians: calculates two Gaussian blur images from the original image and subtracts one from the other. \(\sigma\) values are varied as usual, so \(\frac{n(n-1)}{2}\) feature images are added to the stack.
- Membrane projections: enhances membrane-like structures of the image through directional filtering. The initial kernel for this operation is hardcoded as a \(19\times19\) zero matrix with the middle column entries set to 1. Multiple kernels are created by rotating the original kernel by 6 degrees up to a total rotation of 180 degrees, giving 30 kernels. Each kernel is convolved with the image and then the set of 30 images are Z-projected into a single image via 6 methods:
- sum of the pixels in each image
- mean of the pixels in each image
- standard deviation of the pixels in each image
- median of the pixels in each image
- maximum of the pixels in each image
- minimum of the pixels in each image
Each of the 6 resulting images is a feature. Hence pixels in lines of similarly valued pixels in the image that are different from the average image intensity will stand out in the Z-projections.
- Mean, Variance, Median, Minimum, Maximum: the pixels within a radius of \(\sigma\) pixels from the target pixel are subjected to the pertinent operation (mean/min etc.) and the target pixel is set to that value.
- Anisotropic diffusion: the anisotropic diffusion filtering from Fiji with \(20\) iterations, \(\sigma\) smoothing per iterations, \(a_{1}=0.10, 0.35\), \(a_{2}=0.9\), and an edge threshold set to the membrane size.
- Bilateral filter: is very similar to the Mean filter but better preserves edges while averaging/blurring other parts of the image. The filter accomplishes this task by only averaging the values around the current pixel that are close in color value to the current pixel. The ‘closeness’ of other neighborhood pixels to the current pixels is determined by the specified threshold. I.e. for a value of 10 each pixel that contributes to the current mean have to be within 10 values of the current pixel. In our case, we combine spatial radius of \(5\) and \(10\), with a range radius of \(50\) and \(100\).
- Lipschitz filter: from Mikulas Stencel plugin. This plugin implements Lipschitz cover of an image that is equivalent to a grayscale opening by a cone. The Lipschitz cover can be applied for the elimination of a slowly varying image background by subtraction of the lower Lipschitz cover (a top-hat procedure). A sequential double scan algorithm is used. We use down and top hats combination, with slope \(s = 5, 10, 15, 20, 25\).
- Kuwahara filter: another noise-reduction filter that preserves edges. This is a version of the Kuwahara filter that uses linear kernels rather than square ones. We use the membrane patch size as kernel size, 30 angles and the three different criteria (Variance, Variance / Mean and Variance / Mean^2).
- Gabor filter: at the moment this option may take some time and memory because it generates a very diverse range of Gabor filters (22). ’ This may undergo changes in the future’. The implementation details are included in this script. The Gabor filter is an edge detection and texture filter, which convolves several kernels at different angles with an image. Each point in a kernel is calculated as \(\frac{\cos \left(2\pi f \frac{x_p}{s_x}+\psi \right) e^{-0.5 \left( \frac{x_p^2}{\sigma_x^2} + \frac{y_p^2}{\sigma_y^2} \right)} }{ 2\pi \sigma_x \sigma_y }\). Gabor filters are band-pass filters and therefore implement a frequency transformation.
- Derivatives filter: calculates high order derivatives of the input image (\(\frac{d^4}{dx^2dy^2},\frac{d^6}{dx^3dy^3},\frac{d^8}{dx^4dy^4},\frac{d^{10}}{dx^5dy^5}\)) using FeatureJ (it requires enabling the ImageScience update site in the updater).
- Laplacian filter: computes the Laplacian of the input image using FeatureJ (it requires enabling the ImageScience update site in the updater). It uses smoothing scale \(\sigma\).
- Structure filter: calculates for all elements in the input image, the eigenvalues (smallest and largest) of the so-called structure tensor using FeatureJ (it requires enabling the ImageScience update site in the updater). It uses smoothing scale \(\sigma\) and integration scales 1 and 3.
- Entropy: draws a circle of radius \(r\) around each pixel; gets the histogram of that circle split in numBins chunks; then calculates the entropy as \(\sum_{p~\mathrm{in}~\mathrm{histogram}} -p*\mathrm{log}_2(p)\), where \(p\) is the probability of each chunk in the histogram. numBins is equal to \(32, 64, 128, 256\). \(r\) is equal to \(\sigma\).
- Neighbors: shifts the image in 8 directions by an certain number of pixel, \(\sigma\). Therefore creates \(8n\) feature images.
When using grayscale images, the input image will be also included as a feature. In the case of color (RGB) images, the Hue, Saturation and Brightness will be as well part of the features.
The detailed implementation of these 2D filters can be found in the source code.
**NOTE*: The features named *Derivatives, Laplacian and Structure belong to the ImageScience suite and need to be activated by enabling the ImageScience update site in the updater.
Training features (3D)
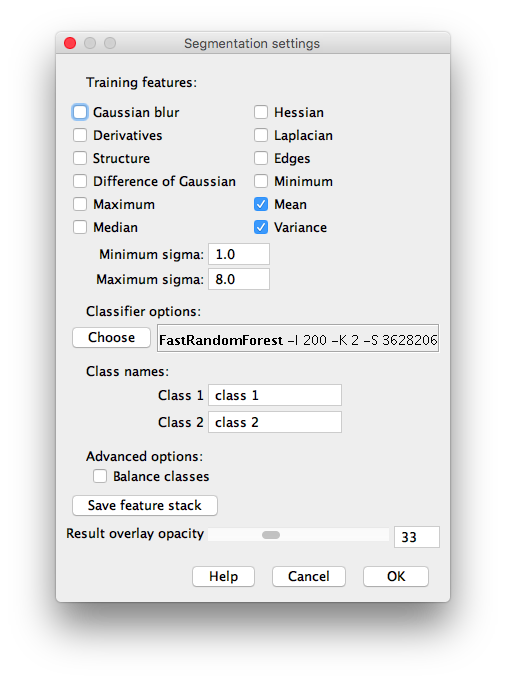 Settings dialog for the Trainable Weka Segmentation 3D plugin.
Settings dialog for the Trainable Weka Segmentation 3D plugin.
When calling the plugin from the menu command Plugins › Segmentation › Trainable Weka Segmentation 3D the set of available image features will be as follows:
- Gaussian blur: performs \(n\) individual 3D convolutions with Gaussian kernels with the normal \(n\) variations of \(\sigma\). The larger the radius the more blurred the image becomes until the pixels are homogeneous.
- Hessian: using FeatureJ it computes for each image element (voxel) the eigenvalues of the Hessian, which can be used for example to discriminate locally between plate-like, line-like, and blob-like image structures. More specifically, it calculates the magnitude of the largest, middle and smallest eigenvalue of the Hessian tensor. It requires enabling the ImageScience update site in the updater. It uses smoothing scale \(\sigma\).
- Derivatives: calculates high order derivatives of the input image (\(\frac{d^4}{dx^2dy^2dz^2},\frac{d^6}{dx^3dy^3dz^3},\frac{d^8}{dx^4dy^4dz^4},\frac{d^{10}}{dx^5dy^5dz^5}\)) using FeatureJ (it requires enabling the ImageScience update site in the updater).
- Laplacian: computes the Laplacian of the input image using FeatureJ (it requires enabling the ImageScience update site in the updater). It uses smoothing scale \(\sigma\).
- Structure: calculates for all elements in the input image, the eigenvalues (smallest and largest) of the so-called structure tensor using FeatureJ (it requires enabling the ImageScience update site in the updater). It uses smoothing scale \(\sigma\) and integration scales 1 and 3.
- Edges: detects edges using Canny edge detection, which involves computation of the gradient magnitude, suppression of locally non-maximum gradient magnitudes, and (hysteresis) thresholding. Again, this feature uses FeatureJ so it requires enabling the ImageScience update site in the updater. It uses smoothing scale \(\sigma\).
- Difference of Gaussian: calculates two Gaussian blur images from the original image and subtracts one from the other. \(\sigma\) values are varied as usual, so \(\frac{n(n-1)}{2}\) feature images are added to the stack.
- Minimum, Maximum, Mean, Variance, Median: the voxels within a radius of \(\sigma\) voxels from the target pixel are subjected to the pertinent operation (mean/min etc.) and the target voxel is set to that value.
Sigma units: all 3D features use a common sigma which is in voxel units. However, since the voxel can be anisotropic, the sigma size will be adjusted accordingly to account for it. Therefore, you need to make sure the input image calibration is correct when you call the plugin.
Feature options
- Membrane thickness: expected value of the membrane thickness, 1 pixel by default. The more accurate, the more precise the filter will be. Only available for 2D features.
- Membrane patch size: this represents the size \(n \times n\) of the field of view for the membrane projection filters. Only available for 2D features.
- Minimum sigma: minimum radius of the isotropic filters used to create the features. By default 1 pixel.
- Maximum sigma: maximum radius of the isotropic filters used to create the features. By default 16 pixels in 2D and 8 pixels in 3D.
Classifier options
.](/media/plugins/tws/aws-classifier-selection.png) Classifier selection in the Trainable Weka Segmentation Settings dialog.
Classifier selection in the Trainable Weka Segmentation Settings dialog.
The default classifier is FastRandomForest, a multi-threaded version of random forest by Fran Supek, initialized with 200 trees and 2 random features per node. However the user can select any available classifier in the Weka by clicking on “Choose” button. By left-clicking on the classifier text we can also edit the classifier options.
If you do not find the classifier you want, you might have to install the Weka package that includes it. For that, you need to launch the Weka GUI Chooser (by clicking on the Weka button of the left panel of the plugin GUI) and use the Weka Package Manager (under Tools › Package manager). For a step-by-step description on how to install new packages, have a look at this tutorial.
Class names
The classes can be renamed using these text boxes.
Balance classes
The classifier uses by the default all the user traces to train. By clicking on this option, we filter first the classes in order to provide a balanced distribution of the samples. This implies that the less numerous classes will duplicate some of their samples and the more populated classes will lose some of their samples for the sake of even distribution. This option is strongly recommended if we want to give the same importance to all classes. An alternative is to use the Weka CostSensitiveClassifier and set a corresponding cost matrix.
Save feature stack
We can save the features as a stack of images by clicking on this button. It will use the last feature configuration that is available.
Result overlay opacity
This slider sets the opacity of the resulting overlay image. Depending on the image contrast of our input images, we might be interested on adjusting this value.
WEKA
The Weka button launches the Weka GUI Chooser, where we can start all the applications available in Weka:
- Explorer: an environment for exploring data with Weka.
- Experimenter: an environment for performing experiments and conducting statistical tests between learning schemes.
- KnowledgeFlow: this environment supports essentially the same functions as the Explorer but with a drag-and-drop interface. One advantage is that it supports incremental learning.
- SimpleCLI: provides a simple command-line interface that allows direct execution of Weka commands for operating systems that do not provide their own command line interface.
For a complete step-by-step description on how to compare classifiers for image segmentation using the Weka Explorer, have a look at the Trainable Weka Segmentation - How to compare classifiers tutorial.
Labels panel
On the right side of the GUI, we have one button and one list of traces for each of the classes defined by the user (two by default: class 1 and class 2).
Add to class button
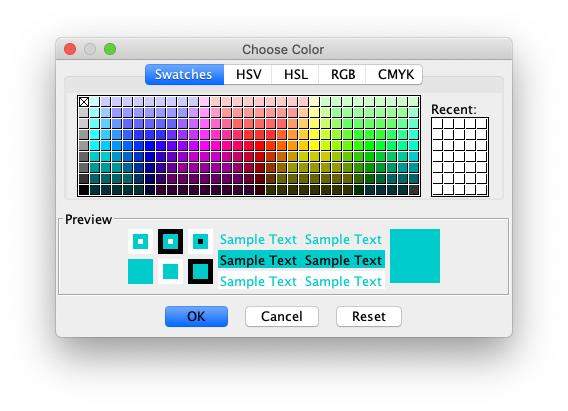 Dialog displayed by right-clicking on the Add to class buttons to select a new color for that class
Dialog displayed by right-clicking on the Add to class buttons to select a new color for that class
By left-clicking on one of the Add to […] buttons, the current selection (ROI) gets added to the class defined by that button. Notice the text of the button can be modified in the Settings dialog as described before.
By right-clicking on any of those buttons, a new dialog will be displayed to change the color associated to that class (and therefore the overlay and result lookup table).
Trace list
Below every Add to […] button there is its corresponding list of added traces (empty by default). By left-clicking on one of the traces, it will be hightlighted in the main image. On the contrary, double clicking on it will remove the trace from the list.
Macro language compatibility
Trainable Weka Segmentation is completely compatible with the popular ImageJ macro language. Each of the buttons in the GUI are macro-recordable and their commands can be reproduced later from a simple macro file. <div class="thumbnail" >
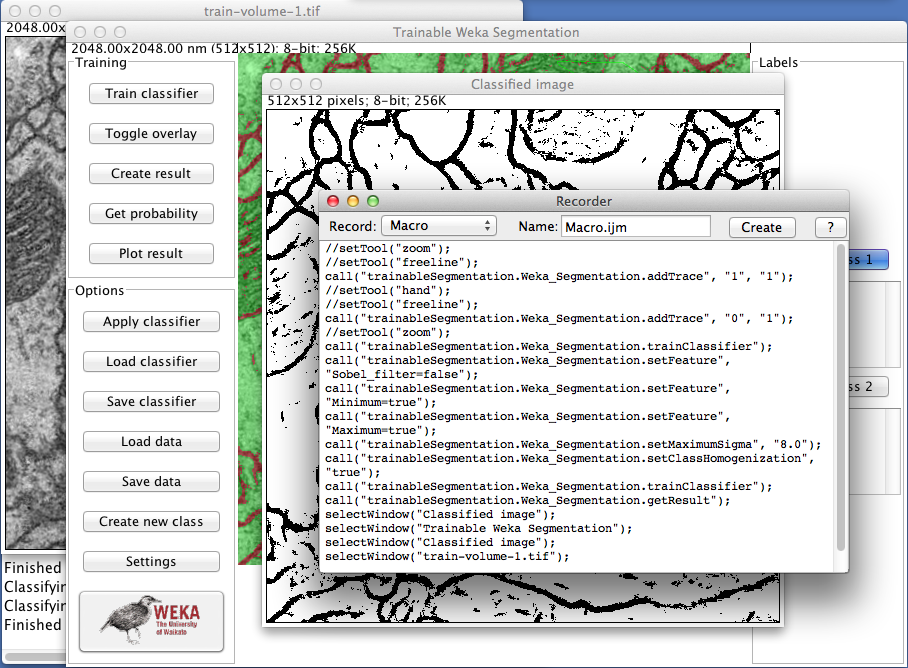 Example of macro recording of the Trainable Weka Segmentation tools.
</div>
Example of macro recording of the Trainable Weka Segmentation tools.
</div>
The complete list of commands is as follows:
-
Start the plugin:
run("Trainable Weka Segmentation"); -
Add traces (current ROI) to a class:
Format: addTrace( class index, slice number )
For example, to add the selected ROI of the first slice to the first class, we type:
```
call("trainableSegmentation.Weka_Segmentation.addTrace", "0", "1");
```
-
Train classifier:
call("trainableSegmentation.Weka_Segmentation.trainClassifier"); -
Toggle overlay:
call("trainableSegmentation.Weka_Segmentation.toggleOverlay"); -
Get the result label image:
call("trainableSegmentation.Weka_Segmentation.getResult"); -
Get probability maps:
call("trainableSegmentation.Weka_Segmentation.getProbability"); -
Plot the model performance curves:
call("trainableSegmentation.Weka_Segmentation.plotResultGraphs"); -
Apply the current classifier to an image or stack:
Format: applyClassifier( input directory, input image or stack, show results flag, store results flag, probability maps flag, store folder)
Example:
```
call("trainableSegmentation.Weka_Segmentation.applyClassifier",
"/home/iarganda/data/", "input-image.tif", "showResults=true",
"storeResults=false", "probabilityMaps=false", "");
```
-
Load a classifier from file:
call("trainableSegmentation.Weka_Segmentation.loadClassifier", "/home/iarganda/classifier.model"); -
Save the current classifier into a file:
call("trainableSegmentation.Weka_Segmentation.saveClassifier", "/home/iarganda/classifier.model"); -
Load previously saved trace data from an ARFF file:
call("trainableSegmentation.Weka_Segmentation.loadData", "/home/iarganda/data.arff"); -
Save current trace data (feature vectors of traces and classes) into a file:
call("trainableSegmentation.Weka_Segmentation.saveData", "/home/iarganda/data.arff"); -
Create new class:
call("trainableSegmentation.Weka_Segmentation.createNewClass", "new-class-name"); -
Launch Weka:
call("trainableSegmentation.Weka_Segmentation.launchWeka"); -
Enable/disable a specific feature:
Format: setFeature( "feature name=true or false" )
Example (enable Variance filters):
```
call("trainableSegmentation.Weka_Segmentation.setFeature", "Variance=true");
```
- Change a class name:
Format: changeClassName( class index, class new name )
Example (change first class name to “background”):
```
call("trainableSegmentation.Weka_Segmentation.changeClassName", "0", "background");
```
-
Set option to balance the class distributions:
call("trainableSegmentation.Weka_Segmentation.setClassBalance", "true"); -
Set membrane thickness (in pixels):
call("trainableSegmentation.Weka_Segmentation.setMembraneThickness", "2"); -
Set the membrane patch size (in pixels, NxN):
call("trainableSegmentation.Weka_Segmentation.setMembranePatchSize", "16"); -
Set the minimum kernel radius (in pixels):
call("trainableSegmentation.Weka_Segmentation.setMinimumSigma", "2.0"); -
Set the maximum kernel radius (in pixels):
call("trainableSegmentation.Weka_Segmentation.setMaximumSigma", "8.0"); -
Set a new classifier:
Format: setClassifier( classifier class, classifier options )
Example (change classifier to NaiveBayes):
```
call("trainableSegmentation.Weka_Segmentation.setClassifier",
"weka.classifiers.bayes.NaiveBayes", "");
```
-
Set the result overlay opacity:
call("trainableSegmentation.Weka_Segmentation.setOpacity", "50");
Complete macro example
// Open Leaf sample
run("Leaf (36K)");
// start plugin
run("Trainable Weka Segmentation");
// wait for the plugin to load
wait(3000);
selectWindow("Trainable Weka Segmentation v3.2.33");
// add one region of interest to each class
makeRectangle(367, 0, 26, 94);
call("trainableSegmentation.Weka_Segmentation.addTrace", "0", "1");
makeRectangle(186, 132, 23, 166);
call("trainableSegmentation.Weka_Segmentation.addTrace", "1", "1");
// enable some extra features
call("trainableSegmentation.Weka_Segmentation.setFeature", "Variance=true");
call("trainableSegmentation.Weka_Segmentation.setFeature", "Mean=true");
call("trainableSegmentation.Weka_Segmentation.setFeature", "Minimum=true");
call("trainableSegmentation.Weka_Segmentation.setFeature", "Maximum=true");
call("trainableSegmentation.Weka_Segmentation.setFeature", "Median=true");
// change class names
call("trainableSegmentation.Weka_Segmentation.changeClassName", "0", "background");
call("trainableSegmentation.Weka_Segmentation.changeClassName", "1", "leaf");
// balance class distributions
call("trainableSegmentation.Weka_Segmentation.setClassBalance", "true");
// train current classifier
call("trainableSegmentation.Weka_Segmentation.trainClassifier");
// display probability maps
call("trainableSegmentation.Weka_Segmentation.getProbability");
Library use
The plugin GUI is independent from the plugin methods. The methods are implemented in a separate file in a library-style fashion, so they can be called from any other Fiji plugin without having to interact with the GUI. This facilitates its integration with other plugins and allows easy scripting.
For examples on how to use the plugin methods from scripts, have a look at the Trainable Weka Segmentation scripting page.
The API of the WekaSegmentation library is available here.
Versatility
), probability of boundaries after training, semantic segmentation into 3 classes (sky, tree, eagle), and detected object using the probability maps of the semantic segmentation and some post-processing ([Level Sets](/plugins/level-sets) from maximum and bounding box selection).](/media/plugins/tws/tws-application-examples.png) Examples of application of Trainable Weka Segmentation. From left to right and from top to bottom: original image of the Berkeley Segmentation Dataset (Test Image #42049 (color)), probability of boundaries after training, semantic segmentation into 3 classes (sky, tree, eagle), and detected object using the probability maps of the semantic segmentation and some post-processing (Level Sets from maximum and bounding box selection).
Examples of application of Trainable Weka Segmentation. From left to right and from top to bottom: original image of the Berkeley Segmentation Dataset (Test Image #42049 (color)), probability of boundaries after training, semantic segmentation into 3 classes (sky, tree, eagle), and detected object using the probability maps of the semantic segmentation and some post-processing (Level Sets from maximum and bounding box selection).
As a pixel classifier, the Trainable Weka Segmentation presents a wide range of applications such as Edge detection, semantic segmentation, or Object detection and localization. All of them at the distance of a few clicks on the plugin GUI and sometimes in combination with other Fiji tools or plugins.
To see who is using Trainable Weka Segmentation and its multiple applications, you can have a look at these publications.
Usage with existing installation of Weka
Weka will automatically load plugins installed in ~/wekafiles. If you already have an existing installation of weka using Java 1.7 and are seeing an error about "java.lang.UnsupportedClassVersionError: weka/filters/unsupervised/attribute/IndependentComponents: Unsupported major.minor version 51.0", then you should remove/rename the ~/wekafiles folder before running Fiji.
Weka core version
Since the 3.2.0 release, Trainable Weka Segmentation uses Weka 3.9.0+ - development version. If you have problems loading models from previous versions of the plugin/library, most likely you need to recreate the models using the new version (see note 1 of the Weka official release).
If you absolutely need to reuse an old model, you can transform it to the new version thanks to a model migrator tool provided by the Weka developers. For more information, check this post in the ImageJ forum.
Troubleshooting
For all questions, suggestions, bug reports and problems related to the Trainable Weka Segmentation plugin or library, please use the ImageJ forum and make sure to check previous posts that might have been done covering the same topic.
Citation
Please note that Trainable Weka Segmentation is based on a publication. If you use it successfully for your research please be so kind to cite our work:
doi:10.1093/bioinformatics/btx180
The Trainable Weka Segmentation code has its own citable DOI.
License
This program is free software; you can redistribute it and/or modify it under the terms of the GNU General Public License as published by the Free Software Foundation (http://www.gnu.org/licenses/gpl.txt).
This program is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details.