The content of this page has not been vetted since shifting away from MediaWiki. If you’d like to help, check out the how to help guide!
Fiji Archipelago is a plugin that brings Cluster functionality to Fiji
Overview
Fiji Archipelago is a tool designed to make it easy for programmers to export Fiji/ImageJ functionality over a network to several other computers.
For the purposes of this article, the root node is the computer from which the cluster is started and managed. Client nodes are computers that perform computations exported from the root node. A program consists of several processes, the computations that are exported to the client nodes.
Client nodes either may be started by the root node, or else the root node may be configured to accept connections from client nodes that have been started manually. By default, communication is done by standard IO over ssh when possible, but may optionally be done via insecure sockets instead.
Requirements
- Root and client nodes should all have the same version of Fiji installed.
- Fiji Archipelago makes use of ssh and ssh key pair authentication, so the server must have a private key file that matches a public key in
authorized_hostson the client. - Server and clients must have access to a shared network file server if file transfer is required.
So far, this has been extensively tested only on Linux machines, but it should be platform-independent.
Features
- On-the-fly addition of new cluster nodes
- Volunteer cluster nodes. A node may be started manually (this has security implications).
- Processes running on nodes that crash or are cancelled are automatically rescheduled.
- Security - root/client communication is done over ssh standard IO by default.
- Easy API - submit Callables to an ExecutorService.
Usage
Existing Archipelago Plugins
The following plugins are available by adding the Archipelago update site.
TrakEM2 Archipelago
This plugin allows clusterized least-squares and elastic alignment in TrakEM2. Right Click in the TrakEM2 canvas window, then select “Setup Cluster…”. If you have not yet started an Archipelago Cluster, you will be prompted to do so. Start the alignment as usual.
Batch Weka Segmentation
This plugin accelerates image classification with the Trainable Weka Segmentation plugin. To use it, create a classifier and save it (ie, a .model file).
Run the batch segmentation plugin by selecting Plugins › Batch › Weka Segmentation 2D.
This plugin is designed for two-dimensional serial sections.
Starting a Cluster
- From the ImageJ window, select Plugins › Cluster › Start Cluster…
The Cluster user interface will open. The cluster must be configured before it may be started.
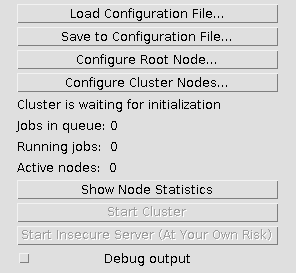
Configure the Root Node
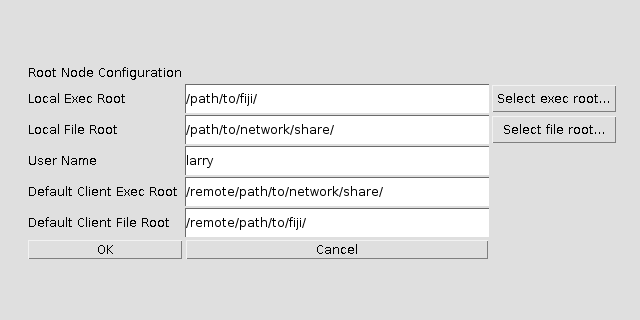
- Click the Configure Root Node… button
- Local Exec Root: The folder containing your local fiji (or ImageJ) executable. This field may disappear in future versions.
- Local File Root: A shared network folder, if one is available. Not necessary for most jobs.
- User Name: Your user name on this machine
- Default Client Exec Root: The folder containing fiji (or ImageJ) on most remote clients. This field may disappear in future versions.
- Default Client File Root: The matching network folder, relative to remote clients.
- Click the OK button
Configure Remote Nodes
Via SSH
Archipelago uses JSch to start remote nodes by ssh. This requires key file authentication, in order for Fiji Archipelago to avoid storing your password. There are two options with regard to how the root and client nodes communicate.
The default is the SSH Shell method, which uses standard IO over ssh for communication. The benefits of this method are that traffic is encrypted and security concerns are deferred to your implementation of ssh.
The other option is the Insecure Socket Shell method, which starts the remote nodes by ssh and causes them to connect to an insecure server running on the root node. This may be faster, but should not be used on an unprotected network.
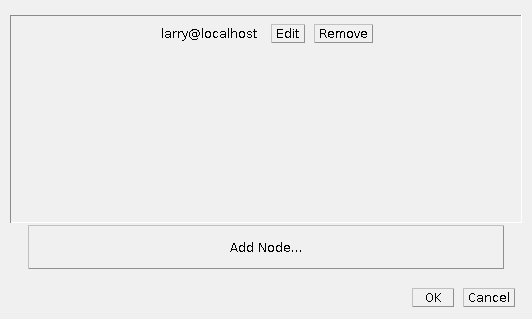
- Click Configure Cluster Nodes…
This will open the cluster node configuration window
- Click Add Node…
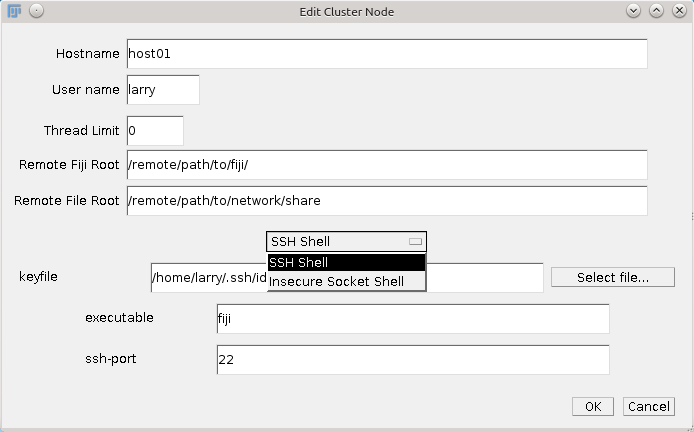
This will open a dialog for adding a new cluster node, with the following fields:
-
- Hostname: The hostname or IP address for this host
- User name: The username for this host
- Thread Limit: Allow up to this many processes to be scheduled on this host. If set to 0, this defaults to the number of available cores.
- Remote Fiji Root: The folder containing fiji or ImageJ on this host.
- Remote File Root: The shared network folder relative to this host.
- Shell: SSH Shell or Insecure Socket Shell
- keyfile: Your ssh keyfile, as generated in Linux by ssh-keygen
- executable: either fiji or ImageJ
- ssh-port: the ssh port for this host
- Click OK
- When you have added all of your nodes, click OK
Via Keyboard
Client nodes may also be started locally, ie, by walking over to them and using a keyboard and mouse (or script). This requires insecure socket connections, and is not recommended on untrusted networks.
On the root node, once the cluster is started, click the Start Insecure Server button.
On the client node:
- Start Fiji
- From the ImageJ window, select Plugins › Cluster › Attach to Cluster…
- Enter the hostname and port for your root node
- Click OK
or
- Run
./fiji --full-classpath --main-class edu.utexas.clm.archipelago.Fiji_Archipelago root.node.hostname port
The default port is 4012.
Configuration on a Proprietary Cluster
Archipelago may be run on a proprietary cluster, for instance one running SLURM or qsub, by scripting the creation of an .arc configuration file and passing it as an argument to the Fiji or ImageJ executable. An example showing how this is done on the vnc queue of the TACC stampede cluster is available.
Saving
Clicking the Save to Configuration File… button will save the current configuration to an xml file for later use. This will save the root node configuration, as well as any nodes that appear in the Configure Cluster Nodes… dialog. This excludes any nodes that have stopped or crashed.
Loading
Click the Load Configuration File… button to load an existing configuration file. This will automatically configure the root node and any client nodes indicated in the file. The cluster should be startable immediately afterward.
Start the Cluster
Click the Start Cluster button. When the cluster is running, this button will change to Stop Cluster. When clicked, the cluster and all running client nodes will stop.
Start the Server
To allow “volunteer nodes” to attach, click the Start Insecure Server button. This starts a server on the default port of 4012. The socket is insecure and unencrypted, and therefore may pose a security risk.
Show Node Statistics
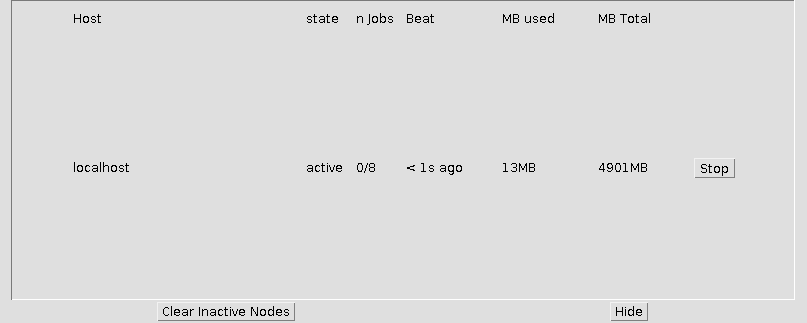
Clicking the Show Node Statistics button will open a dialog that displays usage stats for running client nodes:
- Host: the hostname of the client node in question
- state: the state of the node, active, inactive, or stopped.
- n Jobs: k/n, where there are k running processes out of n available cores.
- Beat: Client nodes send a heartbeat message to the root node approximately once per second. This indicates the length of time since the last heartbeat was received.
- MB Used: The number of megabytes of RAM used by Fiji’s JVM on the client node.
- MB Total: The number of megabytes of RAM that are available to the remote JVM.
- Stop: Click this button to shut the client node down. Any running processes will be rescheduled on other nodes, once they become available.
Debug Output
Select this checkbox if you would like to display debug output on your command line. This is potentially verbose, but should include useful information if your cluster behaves erroneously.
Programmers
The Cluster class provides ExecutorServices through Cluster.getService(n). The argument n may be either an int or a float. If an int, any processes submitted to the ExecutorService are assumed to require n number of cores. If a float, processes are assumed to require a fraction n of the available resources of any given computer. For most usage cases, Cluster.getCluster().getService(1) will return the desired service.
To make this work, submissions to a Cluster are serialized and transmitted to a remote instance of Fiji. The returned result is serialized remotely, then retrieved by the root node. Any submitted Callable or Runnable must implement Serializable. Failure to do so will result in a NotSerializableException at runtime. A consequence of Serialization is that the deep equality of objects is not preserved. In other words, a Callable that is designed to return an object that has been instantiated prior to submission will effectively return a clone.
While many Clusters may exist on a single root node, only one is “official.” This instance is referenced by Cluster.getCluster(). Cluster.activeCluster() indicates whether there is existing active Cluster.
An example may be found in Cluster_SIFT. An example that demonstrates the breakage of deep equality may be found in Equality_Example