The Data File
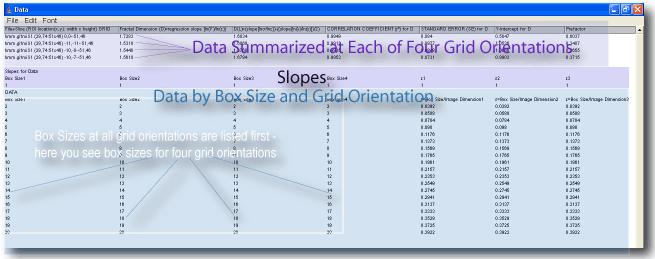
This page helps you sort out the information in the data file. If you need to learn how to set up a scan and get a data file in the first place, click here.The data file has three main parts: summarized data, slopes, and data by box size. It lists information according to grid orientation. There is always only one row of slopes, and as many rows in the bottom as there are box sizes. However, if there was only one orientation in the scan, then there is one row in the top, and one column for each parameter in the bottom; otherwise, if there are G grid orientations, there are G rows in the top, and G columns for each parameter in the bottom.
Click on one of the three major parts of the screen shot of a data file below, or scroll down to read the listings.
TOP of the file
Data Summarized at Each Grid Orientation
The column headings across the top part of the file are explained in this section.
SLOPES
The middle part of the file lists slopes for the data columns for a grid orientation against their respective column for ε. That is, each slope is for the column heading directly below it and the column of εs which has listed in its heading the same number for grid location.
The Data
The bottom part of the file lists data for each box size. Beside each heading is a number (:1, :2, :3 etc.) for matching it with the relevant grid orientation.