This page describes the technical structure of SciJava projects.
- For information on the social structure, see Governance.
- For information on the legal structure, see Licensing.
This page describes the technical structure of SciJava projects, including ImageJ2, ImgLib2, SCIFIO, and other projects built on their foundations. For maximum benefit, we suggest readers familiarize themselves with Maven, Git and GitHub before reading the sections here.
Definitions
Throughout this article, and elsewhere on this wiki, we use the following terms:
- A software component is a program, such as a plugin, or a library of reusable functions. Components are typically designed to work together, and combined to form a software application such as ImageJ. In Maven terms, a component is a single artifact, typically a JAR (file format).
- A software project is a more general term referring to either a single component or a collection of related components. For example, the phrase “ImageJ2 project” refers to several components including ImageJ Common, ImageJ Ops, ImageJ Legacy and the ImageJ Updater.
- The SciJava component collection is the set of all components managed by the
pom-scijavaBill of Materials. Such SciJava components reside across several different architectural layers. See “Bill of Materials” below for details. - SciJava core components are SciJava components of the SciJava component layer itself. See “Organizational structure” below.
- The ImageJ2 software stack is the set of components upon which ImageJ2 is built. It includes components from the SciJava, ImgLib2, ImageJ+ImageJ2, and SCIFIO foundational layers; see “Organizational structure” and “Core libraries” below for details.
SciJava project structure
The ImageJ2 project, and related projects in the SciJava software ecosystem, are carefully structured to foster extensibility.
Organizational structure
There are four organizations on GitHub which form the backbone of the SciJava ecosystem:
- scijava - for SciJava core components: general-purpose, non-image-specific libraries.
- imglib - for ImgLib2 components: flexible N-dimensional image processing.
- imagej - for ImageJ+ImageJ2 components: metadata-rich image library and application.
- scifio - for SCIFIO components: scientific image I/O and file formats.
Each organization contains several related components under its respective umbrella: a core library (see below) and several extensions. In social terms, each organization represents a collection of conceptually related components developed by a distinct team of developers.
Additional organizations can further extend this structure. For example, the Fiji project has several organizations as follows:
- fiji - for Fiji components
- bigdataviewer - for BigDataViewer components
- trakem2 - for TrakEM2 components
Furthermore, many groups maintain their own GitHub organizations with components built on SciJava et al. Here are a few examples:
- LOCI – uw-loci
- FLIMJ – flimlib
- DAIS – TrnDy
- Florian Jug – juglab
- Stephan Saalfeld – saalfeldlab
- Stephan Preibisch – PreibischLab
- <your organization here!>
Git repositories
Each component is contained in its own Git repository, so that interested developers can cherry-pick only those parts of interest. Version control is an indispensable tool to ensure scientific reproducibility (see below) by tracking known-working states of the source code, and maintain a written record of how and why the code has changed over time. For technical details, see the Git section.
Why separate Git repositories?
With Maven it is possible to create a multi-module reactor that unifies several component artifacts into a single build, typically within a single Git repository.
While many SciJava components used to be structured this way, we found that lumping multiple components into a single Git repository with a multi-module build has disadvantages compared to separate Git repositories with single-module builds:
- Typically, components of a multi-module project are all versioned together, but we have opted for individual versioning of components, for reasons of rapid iteration, extensibility and modularity.
- Individual repositories make it easier for developers to cherry-pick only those components of interest, without building the rest of the code, since dependencies are fetched on demand from remote Maven repositories.
- Concerns are better separated, with each component encapsulating its own codebase, issues, pull requests and technical documentation.
- Since every component follows a consistent structure, the supporting tools (e.g., these scripts) are simpler to develop and maintain.
Of course, there are downsides, too:
- Changes affecting multiple components must be done as separate patch sets (i.e., commits or pull requests).
- Issues relevant to multiple components must be filed separately in each issue tracker and cross-referenced.
- It can be more difficult to locate code of interest, since the codebase is spread across so many repositories.
As a rule of thumb, we find that multi-module Maven projects stored within a single Git repository are a natural fit for “big bang” software which is versioned in lockstep and carefully tested before each release, whereas single-module projects stored in separate Git repositories work well for the RERO-style release paradigm.
Maven component structure
All components in these organizations use Maven for project management. Each organization has its own Maven groupId. Each component extends the pom-scijava parent POM, which provides sensible build defaults and compatible dependency versions (see “Bill of Materials” below).
|
Logo |
Project |
Organization |
groupId |
|
|
|||
|
|
|||
|
|
|||
|
|
|||
|
|
|||
Bill of Materials
The pom-scijava parent includes a Bill of Materials (BOM) which declares compatible versions of all components of the SciJava component collection in its dependencyManagement section. These versions are intended to be used together in downstream projects, preventing version skew (symptoms of which include ClassNotFoundException and NoSuchMethodError, as well as erroneous behavior in general). This BOM is especially important while some components are still in beta, since they may sometimes break backwards compatibility.
Core libraries
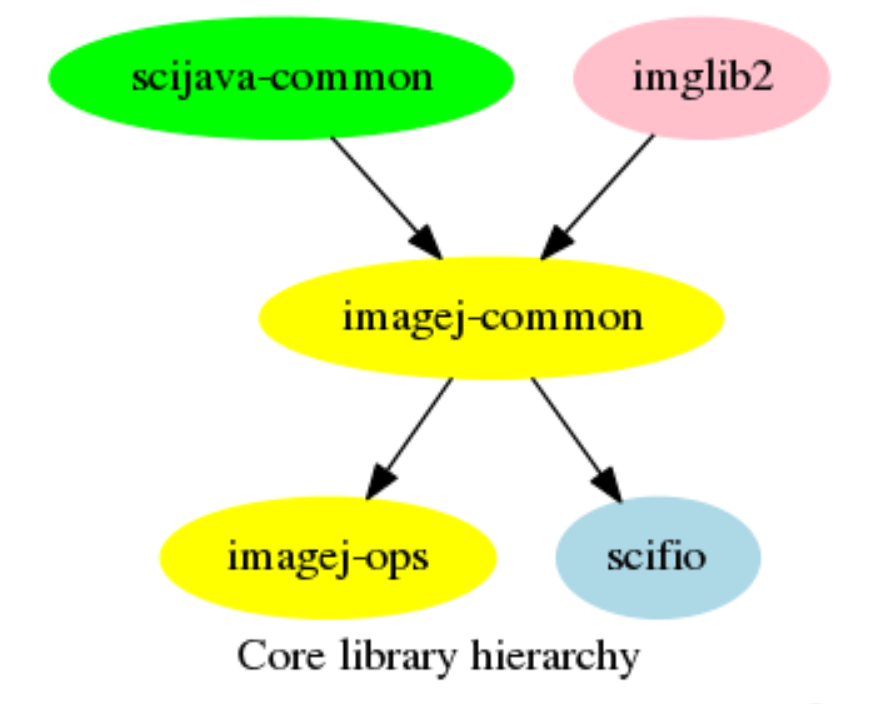
The ImageJ2 software stack is composed of the following core libraries:
- SciJava Common - The SciJava application container and plugin framework.
- ImgLib2 - The N-dimensional image data model.
- ImageJ Common - Metadata-rich image data structures and SciJava extensions.
- ImageJ Ops - The framework for reusable image processing operations.
- SCIFIO - The framework for N-dimensional image I/O.
These libraries form the basis of ImageJ-based software.
The dependency hierarchy of library artifacts is shown in the diagram to the right.
Modularity
Much effort has been expended to ensure the design of these libraries provides a good separation of concerns. Developers in need of specific functionality may choose to depend on only those components which are relevant, rather than needing to add a dependency to the entire ImageJ2 software stack.
Along those lines, the libraries take great pains to be UI agnostic, with no dependencies on packages such as java.awt or javax.swing. The idea is that it should be possible to build a user interface (UI) on top of these libraries, without needing to change the library code itself. We have developed several proof-of-concept UIs for ImageJ using different UI frameworks, including Swing, AWT, Eclipse SWT and Apache Pivot.
Extensibility
Extensibility is ImageJ’s greatest strength. ImageJ provides many different types of plugins, and it is possible to extend the system with your own new types of plugins. See the CreateANewPluginType tutorial for an illustration.
The SciJava Common (SJC) library provides a plugin framework with strong typing, and makes extensive use of plugins itself, to allow core functionality to be customized easily. SJC has an powerful plugin discovery mechanism that finds all plugins available on the Java classpath, without knowing in advance what they are or where they are located. It works by indexing the plugins at compile time via an annotation processor (inspired by the SezPoz project) which writes the plugin metadata inside the JAR file (in META-INF/json/org.scijava.plugin.Plugin). Reading this index allows the system to discover plugin metadata at runtime very quickly without loading the plugin classes in advance.
Reproducible builds
A software version (or build) is called reproducible if it is easy to regenerate the exact same software application from the source code.
For example, you can refer to “ImageJ 1.49g” as a reproducible build, or to Sholl Analysis 3.4.3, while referring to “ImageJ” is irreproducible.
It gets more subtle when making heavy use of software libraries (sometimes called dependencies). It is known, for example, that many plugins in the now-defunct MacBiophotonics distribution of ImageJ worked fine with ImageJ 1.42l, but stopped working somewhere between that version and ImageJ 1.44e. That is: referring to, say, the Colocalisation Analysis plugin does not refer to a reproducible build because it is very hard to regenerate a working Colocalisation Analysis and ImageJ version that could be used to verify previously published results.
Advantages of reproducible builds
Some cardinal reasons to strive for reproducible builds are:
- Reproducible builds are essential for the scientific method (see sidebar right).
- It becomes possible to use a feature branch workflow development style where the main branch is always release ready—or even a continuous delivery approach.
- Debugging with git-bisect becomes feasible.
- As a consequence, it avoids technical debt in favor of a robust development style.
- It attracts more developers to the project, since things “just work” out of the box.
How SciJava achieves reproducible builds
For the reasons stated above, the SciJava software components strive for reproducible builds. The goal is to ensure that code which builds and runs today will continue to do so in exactly the same way for many years to come.
Each component depends on release versions of all its dependencies—never on snapshots or version ranges. A Maven snapshot is a moving target, and depending on one results in an irreproducible build. Similarly, all Maven plugins used, as well as the parent POM, are also declared at release versions. In short: all <version> tags specify release versions, never SNAPSHOT or LATEST versions. We use the Maven Enforcer Plugin to enforce this requirement (though it can be temporarily disabled by setting the enforcer.skip property).
We sometimes use SNAPSHOT versions temporarily on topic branches. However, we always rewrite them before merging to main, to purge all SNAPSHOT references, so that all commits in the history build reproducibly. We use SciJava’s check-branch.sh script to ensure all commits on a topic branch build cleanly with passing tests.
Using snapshot couplings during development
For developing several components in parallel, it can be useful to switch to SNAPSHOT dependency couplings.
You can override the version property of the dependency for which you wish to use a snapshot:
<properties>
<scijava-common.version>LATEST</scijava-common.version>
<enforcer.skip>true</enforcer.skip> <!-- ONLY while depending on a SNAPSHOT -->
</properties>
In the case of Eclipse, you may need to “Update Maven project” in order to see the snapshot couplings go into effect; the shortcut ⌥ Alt + F5 while selecting the affected project(s) accomplishes this quickly.
Current versions of the Eclipse Maven integration (tested with Eclipse Mars) fail to correctly resolve the LATEST version tag to SNAPSHOTs. If this happens to you, try specifying the version explicitly e.g. 2.0.0-SNAPSHOT instead of using LATEST.
Be sure to work on a topic branch while developing code in this fashion. You will need to clean up your Git history afterwards before merging things to the main branch, in order to achieve reproducible builds.
Versioning
SciJava components use the Semantic Versioning system. This scheme communicates information about the backwards compatibility (or lack thereof) between versions of each individual software component. In a nutshell:
Given a version number MAJOR.MINOR.PATCH, increment the:
- MAJOR version when you make incompatible API changes,
- MINOR version when you add functionality in a backwards-compatible manner, and
- PATCH version when you make backwards-compatible bug fixes.
See the Versioning page for a detailed discussion of SciJava versioning.